The Compiler: From Text to Machine Code
Understanding how compilers translate human-readable code into executable programs. Learn the stages of compilation, optimization techniques, and why compile-time analysis is crucial for building reliable software.
In our journey so far, we've explored the two fundamental landscapes of computing. In Subchapter 0.1, we went into the microscopic world of the Central Processing Unit (CPU), witnessing how it tirelessly executes a stream of simple, binary machine instructions. We learned that at its core, a computer only understands numbers-opcodes and operands that tell it to load, store, add, and jump. In Subchapter 0.2, we mapped the vast territory of computer memory, understanding its hierarchical structure from the lightning-fast CPU registers and caches to the more spacious but slower main RAM. We saw how data is organized into the stack and the heap, and how its physical location dramatically impacts program performance.
We now stand at a critical juncture, facing a profound gap. On one side, we have the human world of ideas, logic, and intent, expressed through rich, descriptive language. On the other, we have the machine's world of raw binary, a relentless sequence of ones and zeros. The CPU has no concept of a "user," an "invoice," or a "game character." It only understands instructions like 01101011 and memory addresses like 1111010010101101.
How do we connect these two fundamentally different representations? How do we translate our abstract human thoughts into the concrete, electrical reality the processor can act upon? This is the fundamental problem of programming. The answer, and the subject of this chapter, is the compiler.
The compiler is one of the most essential tools that, we as programmers, should appreciate. It is a master translator, a very-careful quality inspector, and a brilliant optimization engineer, all rolled into one sophisticated program. It takes the source code you write-the text that expresses your logic-and transmutes it into the executable machine code the CPU understands. Understanding what a compiler does is the key to understanding why modern programming languages are designed the way they are. It provides the "why" behind so many of the rules, errors, and features you will encounter.
By the end of this chapter, you will have a strong mental model of the compilation process. You will see how your text file becomes a running program, why certain errors can be caught before your code even runs, and how a compiler can make your programs faster than you might have thought possible. This foundation will prepare you for Chapter 1, where you will write your first line of Rust and meet its world-class compiler, your future partner in building reliable and efficient software.
The Translation Problem
Let's start with a simple, tangible goal. Imagine you want to write a program that adds two numbers. In a human-readable, high-level pseudocode, you might write something like this:
function calculate_sum(x, y):
variable result = x + y
return resultThis is perfectly clear to a human programmer. It expresses an intent: "take two inputs, add them, and give me the sum." But as we learned in Subchapter 0.1, a CPU cannot read this text. It doesn't understand function, variable, result, or even + in this form. It understands machine code.
The compiler's job is to translate the intent of the code above into a sequence of instructions that the CPU can execute. Drawing on our knowledge of CPU instructions and memory, that sequence might look conceptually like this.
First, the program needs to prepare for the function call. This means setting up what we call a "stack frame" in memory for the calculate_sum function - it's where all the function's local variables will live during execution. Remember from Subchapter 0.2 how the stack is this organized section of memory? Well, each function call gets its own little piece of that stack to work with.
Next, we need to get the inputs into the function. The values for x and y have to be passed somehow, and they're typically placed either in specific CPU registers or on the stack. Let's say they're sitting on the stack at memory addresses we'll call [mem_addr_x] and [mem_addr_y] - the compiler knows exactly where they are.
Now comes the actual calculation, and this is where things get interesting. The compiler generates a LOAD register1, [mem_addr_x] instruction to copy the value of x from its memory location into register1. Then it does the same thing for y with a LOAD register2, [mem_addr_y] instruction. With both values now sitting in registers where the CPU can work with them directly, it generates an ADD register3, register1, register2 instruction. This adds the two values and stores the sum in register3.
But we're not done yet - the line variable result = ... in our code tells the compiler it needs a place to hold that sum. So it allocates a spot on the stack for result and generates a STORE [mem_addr_result], register3 instruction to copy the value from the register into that memory location.
When we hit the return result statement, the compiler needs to make this value available to whoever called our function. There's actually a common pattern for this called a "calling convention" - basically an agreed-upon rule for where return values go. Usually, it's a specific designated register like register_return_value. So the compiler generates a LOAD register_return_value, [mem_addr_result] instruction to copy our final sum into that special return register.
After all that work, we need to clean up after ourselves. The program tears down the stack frame for calculate_sum, freeing that memory so it's available for the next function call.
Finally, we return control to the caller with a RETURN instruction, which jumps back to the instruction immediately following where calculate_sum was originally called.
The difference between the simple, three-line function and the seven-step machine process is vast. The compiler is the system that handles this transformation. It reads your high-level, abstract source code and engineers the low-level, concrete sequence of machine instructions that faithfully carries out your logic.
What Is a Compiler?
At its heart, a compiler is a program that translates source code from a high-level programming language to a lower-level language, most often the machine code for a specific CPU. The key characteristic that defines a compiler is that this translation process, called compilation, happens before the program is executed.
This "ahead-of-time" nature is a crucial distinction. It contrasts with an alternative approach used by interpreters. An interpreter reads the source code line-by-line, and for each line, it immediately executes the corresponding actions. It's a "pay-as-you-go" model of translation and execution happening concurrently.
Let's have a little talk about how these two approaches differ fundamentally.
So with the interpreter approach, what happens is that the interpreter processes your source code line by line during execution. When you run the program, the interpreter reads each line, figures out what it means, and immediately executes the corresponding actions. This means translation and execution happen simultaneously - the interpreter must be present every time the program runs. It's like having google translate always ON, translating each sentence as you speak/hear.
The compiler approach works completely differently. The compiler processes your entire source code before execution even begins. During compilation, which happens once on your development machine, it reads all your code, analyzes it completely, and produces a standalone executable file containing optimized machine instructions. This executable can then run directly on the CPU without the compiler present. And here's the key advantage - since the compiler sees all the code at once, it can make intelligent optimizations and catch errors that wouldn't be visible when processing line by line.
The compiler performs four main tasks before your program ever runs:
First, it reads the entire program. Unlike an interpreter, a compiler gets to see the whole picture at once. It knows about every function, every variable, and every file that makes up your project. This comprehensive view is what enables everything else it does.
Then it analyzes the program for correctness. It's checking for syntax errors, logical inconsistencies, type mismatches, and other mistakes that can be detected just by reading the code. This is where a lot of the compiler's protective power comes from - it's like having a careful proofreader who catches your mistakes before they become problems.
Next comes optimization. Because it can see the entire codebase at once, the compiler can make clever transformations to the code to make it run faster, use less memory, or be more efficient. It's not just translating your code - it's actually improving it in ways you might not have thought of.
Finally, it produces a new artifact - a standalone executable file containing pure machine code. This file can be run directly by the operating system and the CPU, without needing the original source code or the compiler itself. It's self-contained and ready to go.
This "whole program" analysis is the compiler's key advantage. It allows the compiler to make guarantees and perform optimizations that are simply impossible for an interpreter that only sees one line at a time. This is a central theme we will return to again and again, as it is the philosophical bedrock upon which languages like Rust are built.
The Stages of Compilation: A Conceptual Overview
The journey from a text file to an executable program is a multi-stage pipeline. While the details are incredibly complex, the core concepts are understandable and form a logical progression. The compiler processes your source code through multiple sequential stages, where each stage transforms and refines the code representation until machine-executable instructions emerge.
Stage 1: Text to Tokens (Lexical Analysis)
The first thing a compiler sees is just a stream of characters. The text result = x + y is, to the computer, no different from !#@$%^&*(). The first stage, called lexical analysis or lexing, is to break this raw stream of characters into a sequence of meaningful units, called tokens.
The lexer identifies distinct tokens in your source code by recognizing patterns and boundaries. When processing continuous text without spaces, it needs to identify where one token ends and another begins. For example, in the string "variableresult", it recognizes "variable" as a keyword token and "result" as an identifier token. The lexer performs this tokenization systematically on your entire code.
Given the line of pseudocode:
variable result = x + y;A lexer would scan this text and produce a stream of tokens like this:
[KEYWORD:"variable"] [IDENTIFIER:"result"] [OPERATOR:"="] [IDENTIFIER:"x"] [OPERATOR:"+"] [IDENTIFIER:"y"] [PUNCTUATION:";"]Each token has a type (like KEYWORD, IDENTIFIER, OPERATOR) and often a value (like "result"). Whitespace and comments are typically discarded at this stage, as they are meaningful to humans for readability but not to the program's structure. This process, also known as tokenization, transforms a formless string of text into a structured, preliminary list of the program's "words."
Stage 2: Tokens to Structure (Parsing)
Now that we have a flat list of tokens, the compiler needs to understand how they relate to each other grammatically. This stage is called parsing or syntactic analysis. The parser takes the linear sequence of tokens and attempts to build a hierarchical tree structure that represents the program's grammar. This structure is often called an Abstract Syntax Tree (AST).
The AST captures the true meaning of the code, independent of how it was formatted. For example, x+y and x + y would produce the exact same AST.
Let's take our token stream from the previous stage:
[IDENTIFIER:"result"] [OPERATOR:"="] [IDENTIFIER:"x"] [OPERATOR:"+"] [IDENTIFIER:"y"](We'll ignore the variable keyword and semicolon for simplicity.)
The parser recognizes this sequence as an assignment statement. The thing being assigned (result) is the left-hand side, and the value (x + y) is the right-hand side. The right-hand side is itself an expression: a binary addition. The parser would build a tree structure that looks something like this:
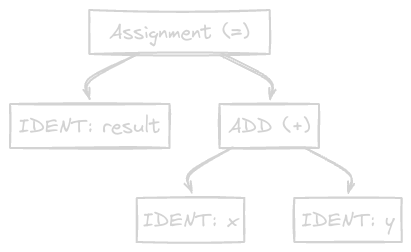
This tree is a much more powerful representation than the flat list of tokens. We can now see programmatically that = is the top-level operation. We know its left child is the destination of the assignment and its right child is the expression to be evaluated. We can see that + is a sub-operation whose inputs are x and y. If the code had a syntax error-for example, result = + y-the parser would be unable to build a valid tree and would report a syntax error.
Stage 3: Understanding Meaning (Semantic Analysis)
We now have a grammatically correct structure (the AST), but we don't yet know if the program makes sense. This is the job of semantic analysis. This stage traverses the AST and enriches it with meaning, checking for logical consistency. It verifies that operations make sense for their data types - just as a syntactically valid statement might still be logically invalid. For instance, the code might have correct syntax but attempt an impossible operation like adding a number to a user object.
Semantic analysis performs several critical checks.
First up is declaration and scope checking. The compiler needs to verify that every variable you're using has actually been declared somewhere. So when it encounters x in your code, it's essentially asking, "Does a variable named x exist in the current scope?" If the answer is no, you'll get that familiar "undeclared variable" error. It's the compiler's way of catching typos and ensuring you're not accidentally referencing something that doesn't exist.
Then there's type checking, which is honestly one of the most important things happening at this stage. The compiler needs to ensure that operations are valid for the types of data involved. Here's what's interesting - when it sees the + node in our AST and realizes that x is a number but y is a string of text (like "hello"), it's going to stop you right there with a type error: "Cannot add a number and a string." This is the compiler enforcing the rules of the language's type system, and it's these rules that prevent a whole class of runtime bugs.
The compiler also verifies function calls, making sure that functions are being called with the correct number and types of arguments. If you try to call a function expecting three parameters with only two arguments, or if you pass a string where a number is expected, the compiler catches it here.
During this process, the compiler builds a symbol table, which is essentially a map of all the identifiers (variable names, function names) in the program to information about them, such as their type, scope, and memory location. After this stage, the compiler has a deep understanding of what your program is intended to do.
Stage 4: Intermediate Representation (IR)
After semantic analysis, many compilers translate the AST into a lower-level, simplified representation of the program called an Intermediate Representation (IR). The IR is an abstraction that sits between the high-level source language and the low-level target machine code.
Why add another step?
Well, the first reason is decoupling. Here's the thing - by introducing IR, you decouple the "front-end" of the compiler (all that lexing, parsing, and semantic analysis we just talked about) from the "back-end" (optimization and code generation). This is actually brilliant when you think about it. You can have multiple front-ends for different languages - C++, Swift, Rust - and they all produce the same IR. Then you can have multiple back-ends that take that IR and generate machine code for different CPUs like x86, ARM, or RISC-V. This is exactly how the popular LLVM compiler infrastructure works.
The second reason is that it massively simplifies optimization. The IR is designed to be very simple and uniform, which makes it so much easier to analyze and transform compared to the original source code's complex AST. Instead of dealing with all the complexity of the source language, you're working with a small set of generic, machine-like instructions - things like add, load, store, and branch. This uniformity is what makes sophisticated optimizations feasible.
Our result = x + y expression might look like this in a conceptual IR:
temp1 = load address_of_x
temp2 = load address_of_y
temp3 = add temp1, temp2
store temp3, address_of_resultThis looks a lot closer to the machine code we saw earlier, but it's still abstract and platform-independent. It doesn't mention specific registers or CPU instructions yet.
Stage 5: Optimization
This is where the magic happens. Working on the IR, the compiler's optimization passes analyze the code to find ways to make it better-usually faster, but sometimes smaller or more energy-efficient. Because the compiler sees the entire program, it can perform incredibly sophisticated transformations. There are hundreds of possible optimizations, but let me walk you through a few common and intuitive examples.
First, there's constant folding. When the compiler sees code like variable screen_width = 1920 * 1080, it's smart enough to realize there's no point making the CPU do this multiplication every time the program runs. So it does the math at compile time and transforms the code into variable screen_width = 2073600. The work is done once, by the compiler, and your CPU never even knows there was a multiplication there.
Then we have dead code elimination, which is pretty fascinating. The compiler analyzes the program's flow and removes code that can never be executed. Look at this example:
// Before Optimization
variable debug_mode = false;
if (debug_mode) {
print("Debugging session started..."); // ... thousands of lines of debug code
}The optimizer sees that debug_mode is always false, so that if condition will never be true. What does it do? It eliminates the entire if block from the final executable, making the program smaller and faster. Those thousands of lines of debug code? They won't even exist in your final binary.
Function inlining is another clever optimization. You know how function calls have a small but measurable overhead - setting up a stack frame, jumping to a new location, all that stuff? For small, frequently-called functions, the compiler can perform inlining, where it replaces the function call with the actual body of the function.
// Before Optimization
function add_one(n):
return n + 1
variable a = 5
variable b = add_one(a)The optimizer might transform this into:
// After Inlining
variable a = 5
variable b = a + 1This eliminates the function call overhead, but here's what's really cool - it also exposes the simplified code (b = 5 + 1) to further optimizations like constant folding, which would turn it into b = 6.
Loop optimizations are where compilers really shine, since loops are often the most performance-critical parts of a program. Compilers have a whole bag of tricks here. They can unroll loops - basically doing multiple iterations' worth of work in one go to reduce branching overhead.
They can also reorder operations inside a loop to make better use of the CPU's internal pipelines and, crucially, to improve memory cache hits. This ties directly back to what we learned in Subchapter 0.2 about memory hierarchies.
Stage 6: Machine Code Generation
The final stage of the pipeline is code generation. The compiler's back-end takes the optimized Intermediate Representation and maps it to the specific instruction set of the target CPU architecture. This is where the abstract, platform-agnostic IR becomes concrete, platform-specific machine code.
This stage involves several critical decisions.
First is instruction selection. For a given IR operation like add, there might be several corresponding machine instructions available. Should it use an instruction that adds a value directly from memory, or one that adds two values already sitting in registers? The code generator has to analyze the context and choose the most efficient sequence of instructions for each situation.
Register allocation is absolutely crucial here - and I mean crucial. As we know from Subchapter 0.1, operations on registers are orders of magnitude faster than operations on main memory. So what the code generator does is analyze which variables are used most frequently and tries to keep those in the CPU's limited set of registers. It only "spills" them to the stack in main memory when absolutely necessary. This is actually one of the most impactful optimizations a compiler performs - the difference between keeping a loop counter in a register versus memory can be dramatic.
Finally, there's memory layout. The compiler makes final decisions about how data gets laid out in memory, especially on the stack. It needs to conform to the platform's "Application Binary Interface" or ABI - basically the agreed-upon rules that ensure functions can call each other correctly across different compilers and libraries.
The output of this stage is an object file, which contains the raw binary machine code along with metadata. A final step, often performed by a separate program called a linker, combines this object file with other object files and system libraries to produce the final executable file that you can run.
Compile Time vs. Runtime
Understanding the distinction between compile time and runtime is perhaps the most important mental model you can build when learning a compiled language. These are two distinct phases in the life of your program, with different actors, different goals, and different constraints.
Compile Time
This is when the developer and the compiler work together.
So when does this happen? It happens once, on your development machine, when you invoke the compiler. The time it takes can vary wildly - anywhere from a fraction of a second for a small program to many minutes or even hours (I hope not) for very large projects.
What's actually happening during this time? The compiler is running through all those stages we discussed - lexing, parsing, semantic analysis, error checking, optimization, and code generation. It's dissecting your source code, understanding its intent, and forging the final executable.
Here's a key insight about the data the compiler works with: it operates only on the source code itself. It has no access to the real data your program will process when a user runs it. The compiler can't know what a user will type, what a file will contain, or what data will come from a network request. All it can do is reason about the types and structure of the data you've described in your code.
The goal here is to produce a correct and highly optimized executable file. The time it takes is actually a secondary concern to the quality of the output - the compiler would rather take an extra second to generate better code than rush and produce something suboptimal.
And the cost of errors at this stage? Well, a "compile-time error" prevents the executable from being created at all. The cost is your time as a developer - you have to fix the error to proceed. But as we'll see, this is actually the cheapest time to find errors.
Runtime
This is when the user runs the program and the CPU executes it.
Runtime happens every single time a user executes your program. This could be billions of times on millions of different machines around the world.
What happens at runtime is fundamentally different from compile time. The operating system loads your compiled machine code into memory, and the CPU begins executing those instructions one by one. The compiler is long gone at this point - it's not involved at all during runtime. Your program is on YOLO mode.
Now the program is working with real, live, and often unpredictable user data. It's reading actual files, accepting keyboard input from real users (and keyboard warriors), processing network packets coming from who knows where. This is the real world, with all its messiness and unpredictability.
The goal at runtime is straightforward but critical: execute the program's logic as quickly and efficiently as possible. Every nanosecond counts here because this is what users experience.
And here's where the stakes get real - the cost of errors at runtime can be catastrophic. A "runtime error" (whether you call it a bug, a crash, or an exception) happens while the program is executing in production. We're talking about data loss for users, security vulnerabilities that could be exploited, server crashes that take down services, or financial losses that can run into millions for a business. This is why moving errors from runtime to compile time is such a big deal.
The fundamental principle of a compiled language is this: do as much work as possible at compile time to make runtime as safe, fast, and predictable as possible. Every check the compiler performs, every error it catches, every optimization it applies is a burden lifted from the runtime environment.
Types of Compilation
The classic "Ahead-of-Time" model we've described is not the only way to translate code. The landscape of language implementation is rich and varied, with different strategies chosen to meet different goals.
Ahead-of-Time (AOT) Compilation
This is the traditional model we have focused on, used by languages like C, C++, and Rust. The entire source code is compiled into a native, standalone executable before the execution phase.
So what are the benefits of AOT compilation?
First and foremost, you get maximum performance. The compiler has both the time and the global view to perform extensive, aggressive optimizations. The resulting machine code is tailored specifically for the target CPU and runs at its full potential.
You also get predictable performance. Since all the compilation work is done upfront, there are no compilation-related pauses or slowdowns during runtime. Your performance is generally very stable - what you measure in testing is what users will experience.
There's also the security and distribution angle. You can distribute the executable file without shipping your source code, which protects your intellectual property. Plus, the end-user doesn't need a compiler or any special tools to run the program - just the executable.
But there are costs to this approach.
The development cycle can be slower. Every time you change the code, you have to wait for it to recompile. This can really slow down rapid iteration, especially on large projects.
There's also platform specificity to deal with. An executable compiled for a Windows machine with an x86 CPU simply won't run on a macOS machine with an ARM CPU. You need to compile a separate version for each target platform.
And sometimes those aggressive optimizations like inlining can increase the size of the final executable file, though usually the performance gains are worth it.
Just-in-Time (JIT) Compilation
JIT compilation is a hybrid approach that seeks to combine the flexibility of interpretation with the speed of compilation. It is used by platforms like the Java Virtual Machine (JVM) and the .NET Common Language Runtime (CLR), for languages like Java, C#, and JavaScript (in modern browsers).
The process typically works like this -
First, the source code gets compiled into an intermediate bytecode, which is a platform-neutral representation - similar to our IR concept we talked about earlier. This bytecode is what gets distributed instead of machine code.
When the user runs the program, a runtime environment like the JVM starts by interpreting this bytecode. It's not running native machine code yet - it's reading and executing the bytecode instructions one by one.
But here's where it gets clever. The runtime monitors the code as it runs, keeping track of which parts get executed frequently. It identifies "hot spots" - those functions or loops that are executed over and over again.
For these hot spots, the JIT compiler kicks in at runtime, compiling that specific piece of bytecode into native machine code for the CPU the program is currently running on. This compiled code is then cached - the runtime remembers it.
So what happens next time that function gets called? Instead of slowly interpreting the bytecode again, it executes the super-fast, native version that was just compiled. The more the program runs, the more of it gets compiled to native code, and the faster it becomes.
What about the benefits of JIT compilation?
Portability is a huge win here. You can distribute a single bytecode file - like a .jar file in Java - that runs on any platform with the necessary runtime environment. Write once, run anywhere, as they say.
But here's where JIT gets really interesting: runtime-informed optimizations. A JIT compiler can make optimization decisions based on how the code is actually being used in production. Say it notices that a certain if statement always evaluates to true in practice. It can compile a specialized version of the function that assumes this is the case, making it much faster. An AOT compiler simply can't do this because it doesn't have access to runtime data.
Of course, JIT has its own costs.
Startup can be painfully slow. The program initially runs in the slower interpreted mode, and there's overhead for the runtime to monitor the code and perform the JIT compilation. This "warm-up" time can be a real problem for certain applications.
Performance can also be unpredictable. The first few times a function runs, it might be slow, then suddenly it becomes fast once it's JIT-compiled. For applications requiring consistent, low latency, this inconsistency can be a dealbreaker.
And don't forget about memory usage - the JIT compiler and its associated runtime machinery must reside in memory alongside your program, which increases your memory footprint.
Transpilation
A third category is transpilation, or source-to-source compilation. A transpiler is a compiler that reads source code in one high-level language and outputs source code in another high-level language.
A very common example is TypeScript. Programmers write code in TypeScript, which provides advanced features like static types. The TypeScript transpiler then translates this code into standard JavaScript, which can be run in any web browser. This allows developers to benefit from the advanced features of TypeScript during development, while still targeting the universally available JavaScript runtime environment.
Static Analysis
We've established that compilers can check for errors at compile time. This general capability is known as static analysis-the process of analyzing a computer program without executing it. This is the compiler's most powerful capability, and it is the primary mechanism through which it validates and protects your code's quality. A language's design deeply influences how much static analysis its compiler can perform.
Type Checking
The most common and fundamental form of static analysis is type checking. As we saw in the semantic analysis stage, the compiler tracks the type of every variable (integer, floating-point number, string of text, custom data structure, etc.). It then uses this information to validate every operation.
So it prevents you from adding a number to a user profile - you can't just write 5 + user_profile and expect it to work. It also prevents you from trying to find the length of a number with something like length(123) - numbers don't have a length property, strings do. And it ensures the data you pass to a function matches what that function expects to receive - if a function wants three integers, you can't pass it two strings and a boolean.
Each type error caught by the compiler is a potential runtime crash, data corruption bug, or security vulnerability that is completely prevented. It's a bug that your users will never experience.
Flow Analysis
More advanced compilers can perform control-flow and data-flow analysis. They can analyze the possible paths of execution through your program to detect potential problems.
Consider this pseudocode:
function process_data(data_source):
variable data;
if (data_source == "network") {
data = fetch_from_network();
} else if (data_source == "file") {
data = read_from_file();
}
// What if data_source was "cache"?
// The variable 'data' would never be initialized!
return process(data);A simple compiler might not see a problem here. But a compiler with sophisticated flow analysis could detect that there are possible paths through this function where the data variable is used without ever being given an initial value. This is a common source of bugs that can lead to unpredictable behavior and crashes. The compiler can flag this and force you to handle all possible cases, for instance, by providing a default value or handling the "cache" case explicitly.
Resource Tracking
Perhaps the most advanced form of static analysis involves tracking the lifecycle of resources like memory, file handles, or network sockets.
Let's talk about memory management first. In many languages, bugs related to memory are both common and severe. Using memory after it's been freed - that's your classic use-after-free bug - or forgetting to free memory altogether, causing memory leaks, can lead to crashes and security exploits. Here's what's amazing though: an advanced compiler can perform static analysis to ensure that every piece of memory is properly managed throughout its entire lifetime. It can guarantee at compile time that these errors simply cannot happen. That's a game-changer for system programming.
The same principle applies to file handles. You know how a program that opens a file should always close it eventually? A compiler with resource tracking capabilities can actually enforce this rule, ensuring that you never accidentally leave a file open. It's not just a best practice anymore - it's guaranteed by the compiler.
This ability to statically verify resource management is a cornerstone of modern systems programming languages and is a key feature that provides immense safety guarantees.
Optimizing Compilers
We've touched on optimization, but it's worth diving deeper to appreciate how a compiler's deep integration with our knowledge of CPU and memory architecture (from Subchapters 0.1 and 0.2) can lead to remarkable performance gains. An optimizing compiler is an expert system for performance engineering.
Register Allocation
We know that CPU registers are the fastest possible place to store data. A good compiler's register allocator is its most critical optimization component. It performs complex greedy algorithms to determine the most effective way to assign variables to the handful of available registers. By keeping frequently accessed data, like a loop counter or an accumulator, in a register for its entire lifetime, the compiler avoids hundreds or thousands of slow main memory accesses, dramatically speeding up the code.
Instruction Selection
CPUs often have specialized, powerful instructions that can do the work of several simpler ones. The compiler's back-end has a detailed model of the target CPU and can perform clever instruction selection.
For example, if you write variable result = a * 8;, the compiler knows that multiplication can be a relatively slow operation. It also knows that on a binary computer, multiplying by 8 is the same as shifting the bits of the number to the left by 3 places. It will likely replace your multiplication with a single, much faster bit-shift instruction (SHL result, a, 3). You write the code that is clear and expresses your intent (* 8), and the compiler chooses the most efficient implementation for the hardware.
Vectorization (SIMD)
In Subchapter 0.1, we introduced SIMD (Single Instruction, Multiple Data) instructions, which allow the CPU to perform the same operation on multiple pieces of data simultaneously. Modern compilers are exceptionally good at auto-vectorization.
Let's re-consider a loop that adjusts the brightness of pixels in an image which we talked about in the last subchapter:
for i from 0 to pixels.length:
pixels[i] = pixels[i] + 10The optimizer can recognize this pattern. Instead of generating code that loads one pixel, adds 10, stores one pixel, and then repeats, it can generate SIMD instructions. It will use a wide SIMD register to load 4, 8, 16 or even 64 pixel values at once, add 10 to all of them with a single SIMD ADD instruction, and then store all the results back to memory in a single go. This can make loops like this many times faster, without the programmer having to write any special, platform-specific code.
Memory Layout and Cache Optimization
Drawing on the principles of Subchapter 0.2, a compiler can also optimize how your data is laid out in memory to improve cache performance. For example, when you define a custom data structure, the compiler might reorder the fields within that structure. It can place fields that are often accessed together next to each other, so they are more likely to be loaded into the same cache line. This avoids situations where accessing one field brings a cache line into memory, but accessing the next field immediately requires fetching a completely different cache line, which is much slower.
These are just a few examples. A modern optimizing compiler is a sophisticated engineering achievement, applying dozens or even hundreds of analysis and transformation passes to turn your clear, high-level code into brutally efficient machine code.
The Limits of Compiler
For all its power, a compiler is still just a tool, and like any tool, it has limitations. It's important to understand what a compiler cannot do.
First off, it can't fix a bad algorithm. A compiler can make a well-written loop run 10% or even 50% faster, sure. But it cannot change your O(n²) bubble sort algorithm into an O(n log n) merge sort. The choice of the high-level algorithm and data structures is still your responsibility and will always have the largest impact on performance. The compiler optimizes the implementation; you design the approach.
It also can't prevent all logical errors. A compiler can ensure you don't add a number to a string - that's type checking. But it cannot know that you typed + when you logically meant to type -. If your business logic is flawed, the compiler will faithfully translate that flawed logic into efficient machine code. The correctness of the program's ultimate goal remains in your hands.
The compiler can't know the future either. It makes all its decisions based on the static source code. It has no knowledge of the specific data the program will encounter at runtime. It can't predict what a user will type into a search box or which branch of an if statement will be taken more often in the real world. This is actually where JIT compilers sometimes have an advantage - they can observe this runtime behavior and adapt.
And finally, it can't violate the laws of physics. A compiler can cleverly arrange memory access to maximize cache hits, but it cannot eliminate the fundamental latency of fetching data from RAM. It can schedule instructions to keep the CPU's pipelines full, but it cannot make the CPU's clock run faster. Optimization has its limits, and those limits are dictated by the physical hardware.
Preparing for Rust
You now have a solid conceptual model of what a compiler is and what it does. This understanding is the key to appreciating the design and philosophy of Rust.
Throughout this chapter, we have seen a recurring theme: there is a trade-off between programmer convenience and the power of compile-time analysis. The more information a compiler has, the more it can help.
Some programming languages are designed to be very "loose," requiring very little upfront information from the programmer. This can make them fast to write code in, but it leaves the compiler without the information it needs. It cannot perform deep static analysis, so it cannot find many bugs, and it cannot perform many optimizations. The burden of correctness and performance falls almost entirely on the programmer and on runtime checks.
Other languages, like Rust, take a different approach. They are designed around a trade-off: the language asks the programmer to be more explicit and provide more information about their intent. You must declare the type of every variable. You must handle all possible outcomes of an operation. And, as you will see, you must abide by a set of rules about how data can be accessed and shared.
In exchange for this upfront effort and information, the Rust compiler can provide an unprecedented level of support.
Here's the key insight: the more a compiler knows about your intent, the more errors it can prevent. By providing detailed type information, you're enabling the compiler to catch entire classes of bugs before your code can even be compiled. This isn't just about catching typos - we're talking about eliminating whole categories of errors.
And there's a performance angle too. The more guarantees a compiler has, the more aggressively it can optimize. When the Rust compiler can prove certain properties about your code - for example, that two pieces of code cannot possibly interfere with each other's data - it can perform optimizations that would be unsafe in other languages. The optimizer can apply aggressive transformations because it knows exactly what's safe.
But here's what really sets modern compilers apart: they can track complex properties like memory ownership and data flow. The Rust compiler, as we'll discover, uses an advanced form of static analysis to track the ownership and lifecycle of every piece of memory in the program. This allows it to guarantee, at compile time, that common and devastating memory bugs like use-after-frees or data races are impossible. Think about that - an entire category of runtime errors, caught during compilation where they can be fixed cheaply.
This is why understanding the compiler is so crucial. When you begin writing Rust, you will find its compiler (rustc) to be strict, careful, and sometimes demanding. But you will now understand that it is not being difficult. It is gathering the information it needs to fulfill its role: to protect you from bugs and to generate code with world-class performance.
Phew... that was a lot
The compiler is a fundamental tool in software development. It systematically transforms your source code into executable machine instructions. It converts human-readable programming languages into the binary instructions that CPUs execute.
We've traced an awesomejourney from a simple text file through a pipeline of transformation: from characters to tokens, from tokens to a structured tree, from that tree to a simplified intermediate form, and finally, from that form to the raw binary instructions that command the CPU. Along the way, we've seen the compiler act as a quality inspector, using static analysis to check our logic and catch bugs before they are born, and as a performance engineer, using a deep understanding of the hardware to optimize our code in ways we could never do by hand.
We have firmly established the two worlds of compile time and runtime, and we understand that the central philosophy of a language like Rust is to do as much work as possible in the safe, static world of the compiler to make the dynamic, unpredictable world of the user as fast and reliable as it can be.
This knowledge is the foundation upon which you will build your understanding of Rust. Every feature of the language, from its type system to its famous ownership model, is designed to empower the compiler to help you.
In the next chapter, we will finally leave the world of concepts and enter the world of practice. You will install the Rust toolchain, write your first "Hello, world!" program, and invoke the Rust compiler for the first time. When you see it process your code, you will now have a clear mental model of the incredible, complex, and powerful process that is happening behind the scenes. You will be ready to work with this sophisticated tool for writing correct, fast, and reliable software.